1.MQ引言
1.1 什么是MQ
MQ(Message Quene) : 翻译为 消息队列,通过典型的 生产者和消费者模型,生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,轻松的实现系统间解耦。别名为 消息中间件 通过利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
1.2 MQ有哪些
当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ,Kafka,阿里巴巴自主开发RocketMQ等。
1.3 不同MQ特点
1 | # 1.ActiveMQ |
RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
2.RabbitMQ 的引言
2.1 RabbitMQ
基于
AMQP协议,erlang语言开发,是部署最广泛的开源消息中间件,是最受欢迎的开源消息中间件之一。
官方教程: https://www.rabbitmq.com/#getstarted
1 | # AMQP 协议 |
2.2 RabbitMQ 的安装
2.2.1 下载
官网下载地址: https://www.rabbitmq.com/download.html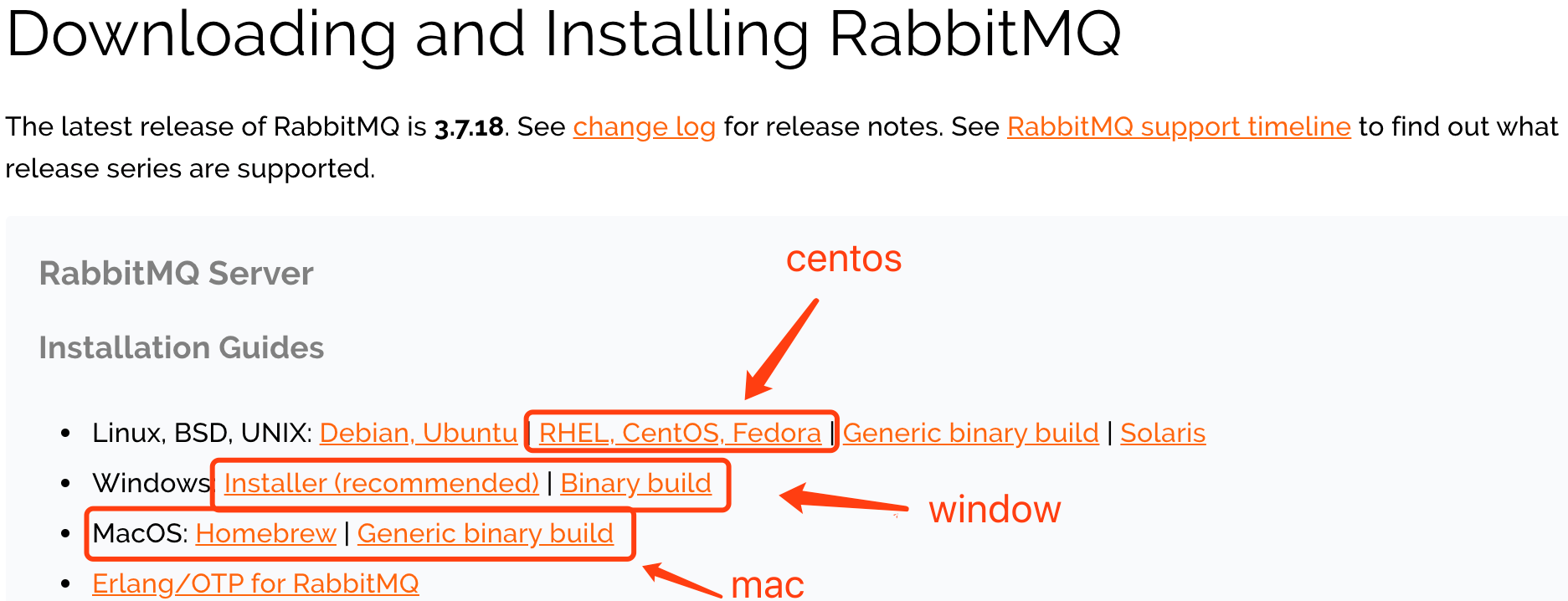
2.2.2 下载的安装包!
注意:这里的安装包是centos7安装的包
2.2.3 安装步骤
1 | # 1.将rabbitmq安装包上传到linux系统中 |
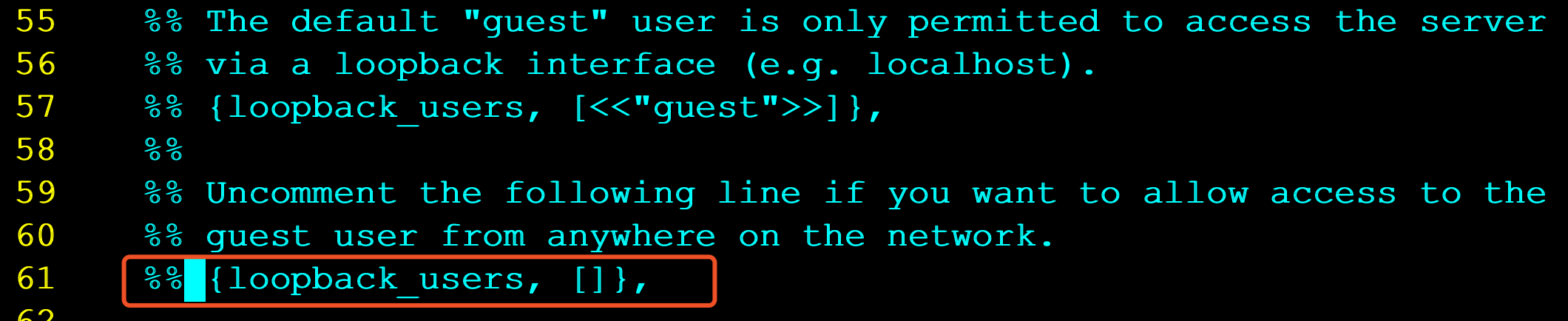
将上图中配置文件中红色部分去掉%%,以及最后的,逗号。修改为下图:
1 | # 7.执行如下命令,启动RabbitMQ中的插件管理 |
1 | # 10.关闭防火墙服务(或者打开15672端口) |
1 | # 12.登录管理界面 |
3. RabiitMQ 配置
3.1RabbitMQ 管理命令行
1 | # 1.服务启动相关 |
3.2 web管理界面介绍
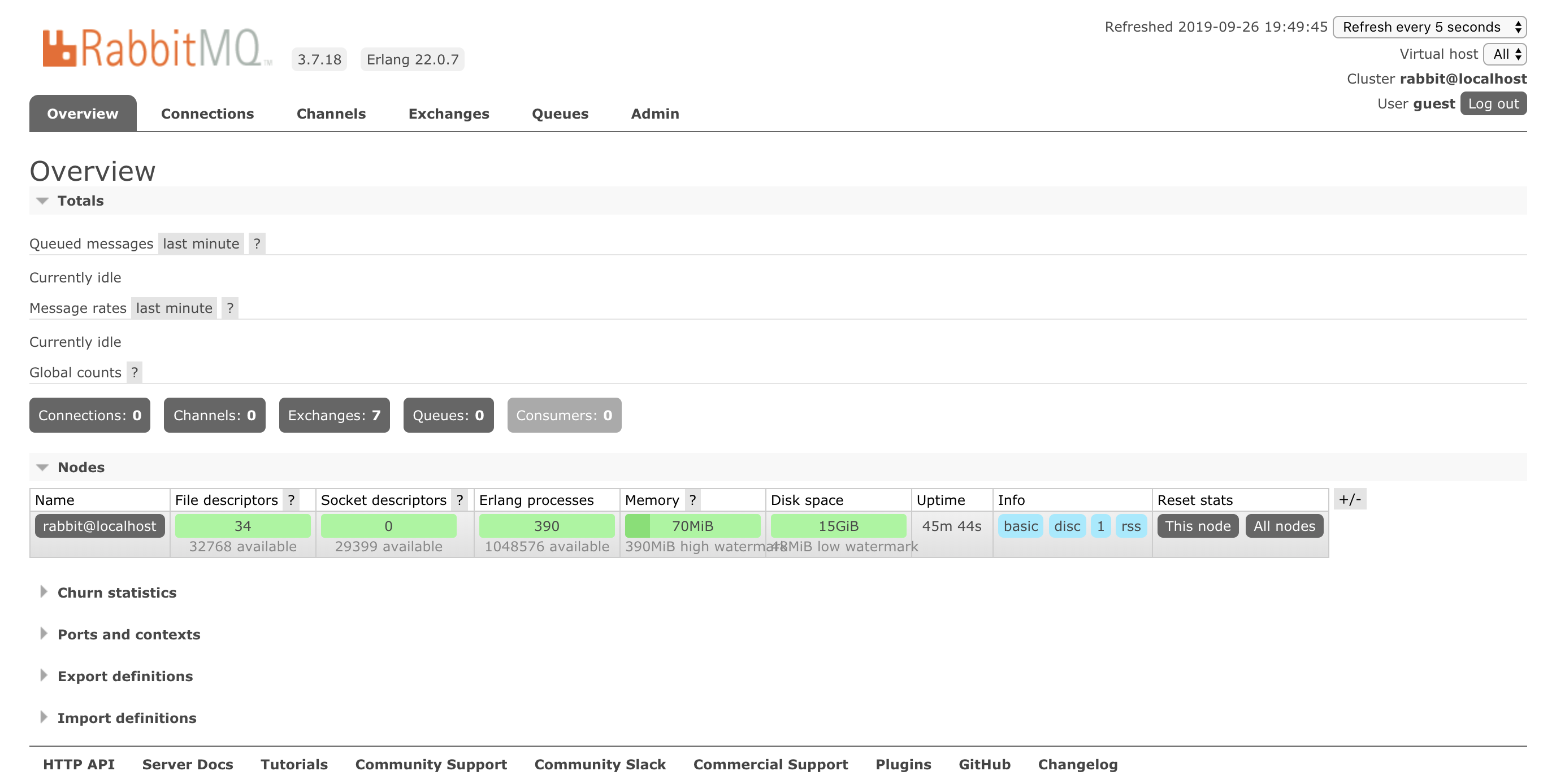
3.2.1 overview概览
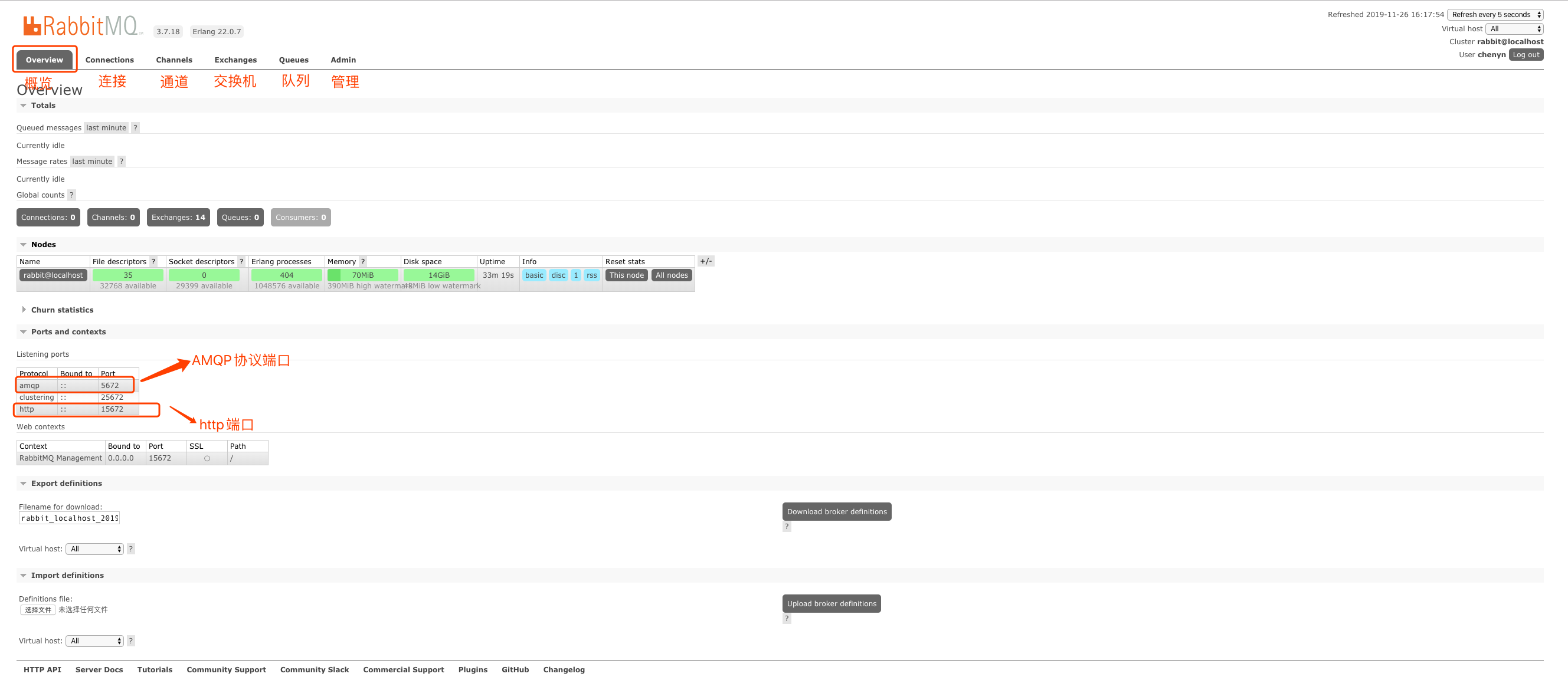
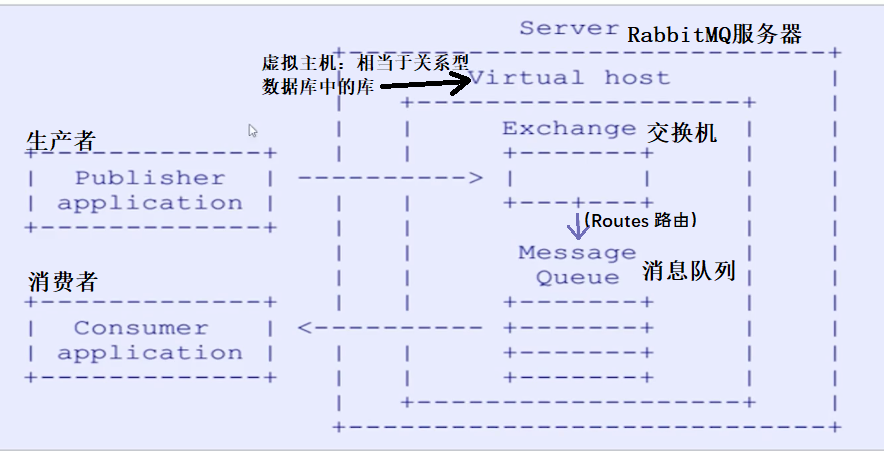
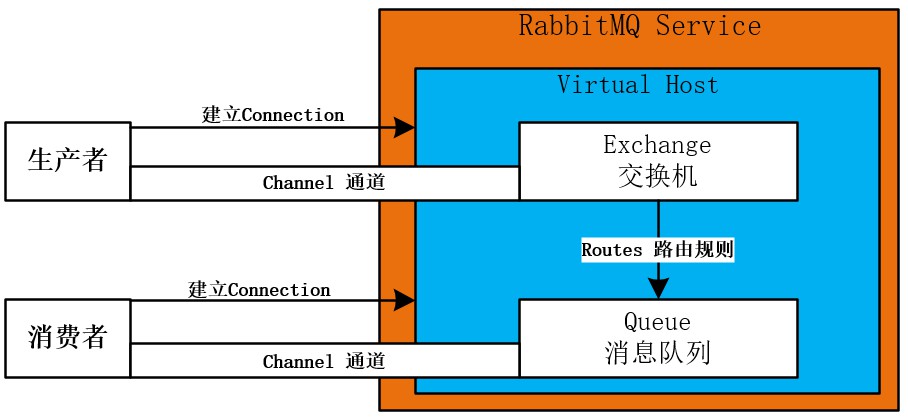
connections:无论生产者还是消费者,都需要与RabbitMQ建立连接后才可以完成消息的生产和消费,在这里可以查看连接情况。channels:通道。建立连接后,会形成通道。消息的投递获取依赖通道。Exchanges:交换机。用来实现消息的路由。Queues:队列,即消息队列。消息存放在队列中,等待消费,消费后被移除队列。Admin:对用户进行管理。
3.2.2 Admin用户和虚拟主机管理
1. 添加用户
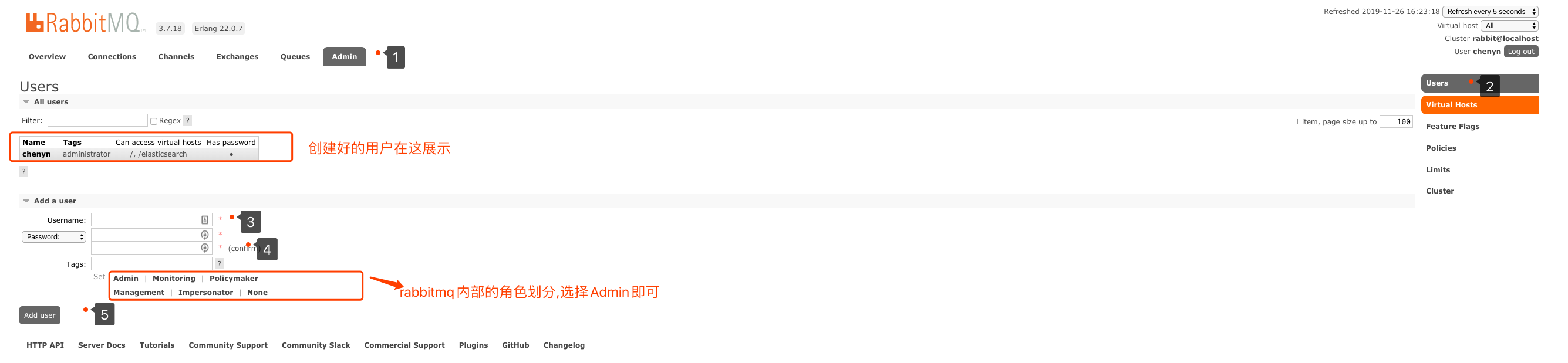
上面的Tags选项,其实是指定用户的角色,可选的有以下几个:
超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
2. 创建虚拟主机
1 | # 虚拟主机 |

3. 绑定虚拟主机和用户
创建好虚拟主机,我们还要给用户添加访问权限:
点击添加好的虚拟主机:

进入虚拟机设置界面: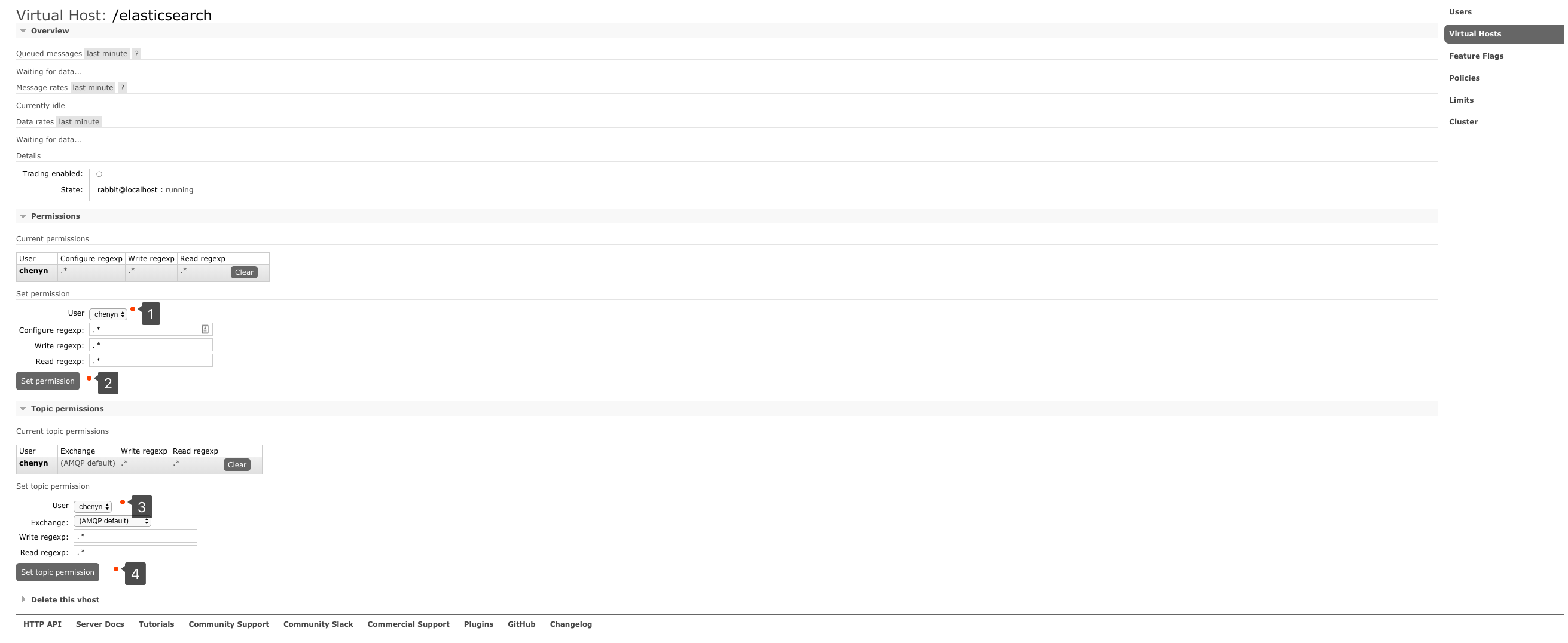
4.RabbitMQ 的第一个程序
4.0 AMQP协议的回顾
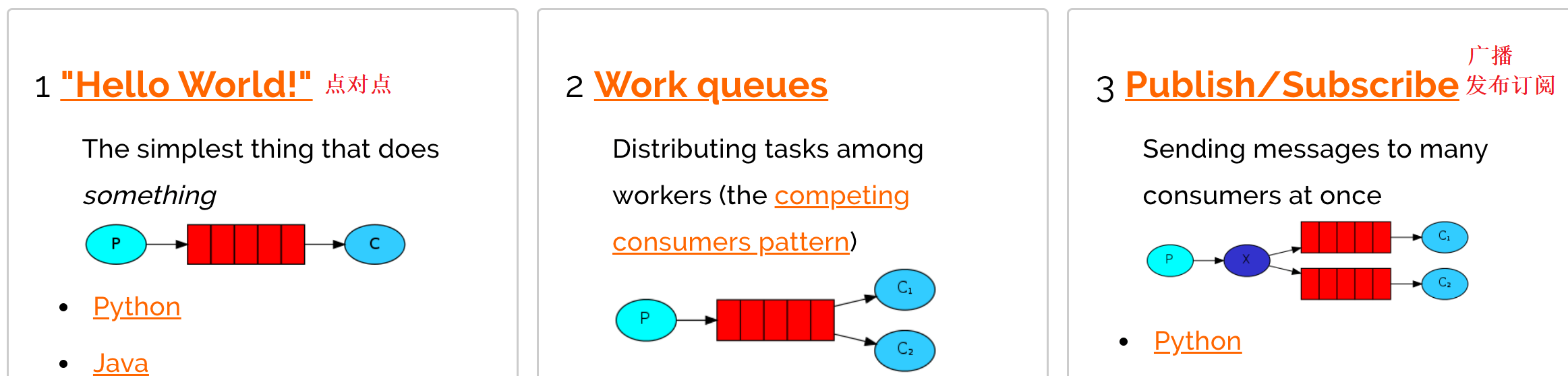
4.1 RabbitMQ支持的消息模型
4.2 引入依赖
1 | <dependency> |
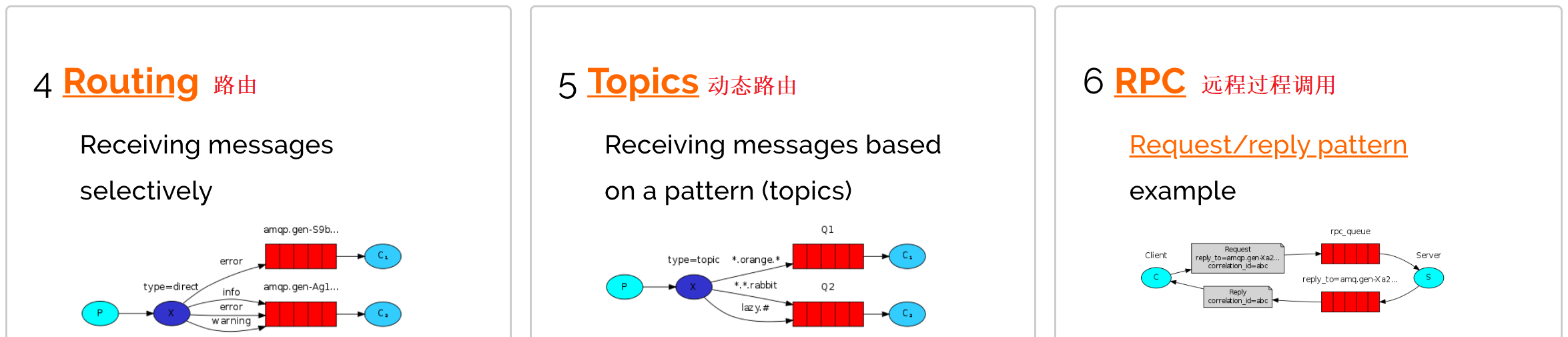
4.3 第一种模型(直连)
在上图的模型中,有以下概念:
- P:生产者,也就是要发送消息的程序。
- C:消费者:消息的接受者,会一直等待消息到来。
- queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
1. 消息生产者
1 | // 生产消息 |
2. 消息消费者
1 | // 消费消息(在main中测试,是为了保证消费者一直处于监听状态,不会自动停止。) |
3. 封装连接工具类
1 | // 简单地封装以下 供测试使用 |
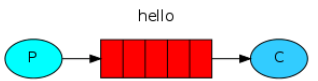
4.4 第二种模型(work quene)
Work queues,也被称为(Task queues),任务模型。当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用work 模型:让多个消费者绑定到一个队列,共同消费队列中的消息。队列中的消息一旦消费,就会消失,因此任务是不会被重复执行的。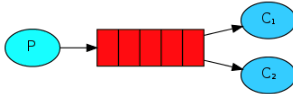
角色:
- P:生产者:任务的发布者
- C1:消费者-1,领取任务并且完成任务,假设完成速度较快
- C2:消费者-2:领取任务并完成任务,假设完成速度慢
1. 生产者
1 | channel.queueDeclare("hello", true, false, false, null); |
2.消费者-1
1 | channel.queueDeclare("hello", true, false, false, null); |
3.消费者-2
1 | channel.queueDeclare("hello", true, false, false, null); |
4.测试结果
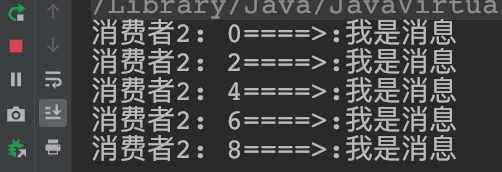
总结:在不做任何设置的情况下,RabbitMQ将按顺序将每个消息发送给下一个使用者。
平均而言,每个消费者都会收到相同数量的消息。这种分发消息的方式称为循环。
上面遇到的问题:消费者2的处理速度比消费者1慢,而我们采用的是平均分配,这就导致消费者2拖慢了系统的允许速度。
我们希望处理快的能多处理一些消息,处理慢的就少处理一些,能者多劳。这就要使用消息种动确认机制。
5.消息自动确认机制
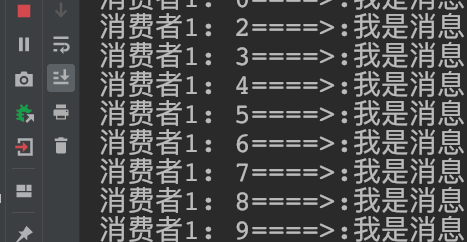
假设消费者2已经被系统分配了5个消息,这5个消息就会被RabbitMQ标记为清除。
当消费到第3个消息的时候,消费者自己宕机了,那么还剩2个消息就丢失了。
我们希望未被处理的消息能够交给消费者1进行处理,而不是丢失。
1 | /* |
结果:
4.5 第三种模型(fanout)
fanout 扇出 也称为广播
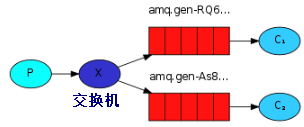
在广播模式下,消息发送流程是这样的:
- 可以有多个消费者。
- 每个消费者有自己的queue(队列)。
- 每个队列都要绑定到Exchange(交换机)。
- 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
- 交换机把消息发送给 绑定过此交换机的所有队列。
- 队列的消费者都能拿到消息。实现一条消息被多个消费者消费。
1. 生产者
1 | /* |
2. 消费者-1
1 | // 绑定交换机(可以用声明交换机的方式来绑定) |
3. 消费者-2
1 | // 绑定交换机(可以用声明交换机的方式来绑定) |
4.消费者-3
1 | // 绑定交换机(可以用声明交换机的方式来绑定) |
5. 测试结果



4.6 第四种模型(Routing)
4.6.1 Routing 之订阅模型-Direct(直连)
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的交换机(Exchange)。
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
流程:
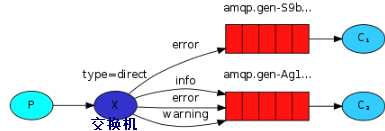
图解:
- P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
- X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列。
- C1:消费者,其所在队列指定了需要routing key 为 error 的消息。
- C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息。
1. 生产者
1 | /* |
2.消费者-1
1 | // 绑定交换机(可以用声明交换机的方式来绑定) |
3.消费者-2
1 | // 绑定交换机(可以用声明交换机的方式来绑定) |
4.测试生产者发送Route key为error的消息时


5.测试生产者发送Route key为info的消息时(此时消息队列中已经有error的消息了)


4.6.2 Routing 之订阅模型-Topic
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
试想如果没有通配符,代码冗余情况:
1 | channel.queueBind(queue, "logs_direct", "error2"); |
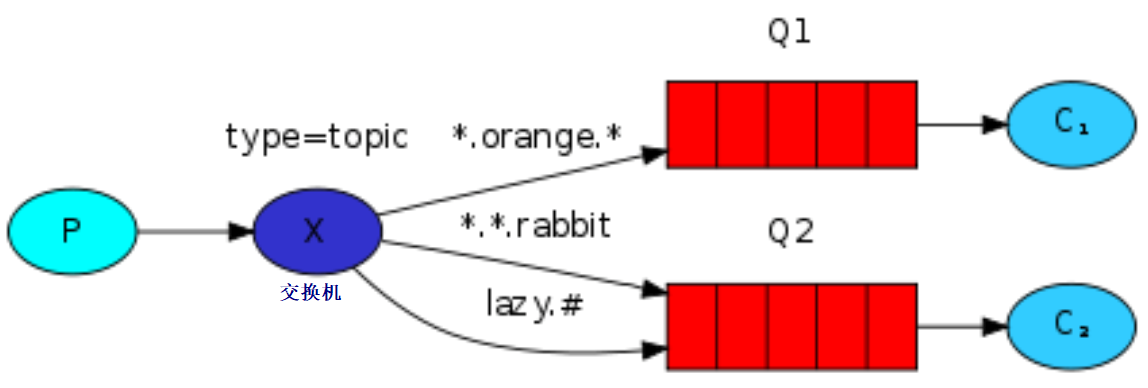
1 | 这种模型Routingkey一般都是由一个或多个单词组成。 |
1.生产者
1 | /* |
2.消费者-1
Routing Key中使用*通配符方式
1 | // 声明交换机 |
3.消费者-2
Routing Key中使用#通配符方式
1 | //声明交换机 |
4.测试结果


5. SpringBoot中使用RabbitMQ
5.0 搭建初始环境
1. 引入依赖
1 | <dependency> |
2. 配置配置文件
1 | spring: |
5.1 第一种hello world模型使用
生产者
RabbitTemplate用来简化操作,使用时候直接在项目中注入即可使用。1
2
3
4
5
6
7
8
private RabbitTemplate rabbitTemplate;
public void testHello(){
// 转换and发送:发送内容"hello world"(发送内容的类型可为任意类型)
rabbitTemplate.convertAndSend("hello", "hello world");
}消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/*
消费者监听hello队列,若没有hello队列,则自动创建。
@Queue:设置消息队列属性(消息队列名、是否独占、是否自动删除等)。
*/
(queuesToDeclare = ("hello"))
public class HelloCustomer {
/*
@RabbitHandler:代表此方法是从队列中取出消息时的回调方法
message:从队列中取出的消息
*/
public void receive1(String message){
System.out.println("message = " + message);
}
}
5.2 第二种work模型使用
生产者
1
2
3
4
5
6
7
8
9
private RabbitTemplate rabbitTemplate;
public void testWork(){
for (int i = 0; i < 10; i++) {
rabbitTemplate.convertAndSend("work", "hello work!");
}
}消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
public class WorkCustomer {
(queuesToDeclare = ("work"))
public void receive1(String message){
System.out.println("work message1 = " + message);
}
(queuesToDeclare = ("work"))
public void receive2(String message){
System.out.println("work message2 = " + message);
}
}说明:默认在Spring AMQP实现中Work这种方式就是公平调度,如果需要实现能者多劳需要额外配置。
5.3 Fanout 广播模型
生产者
1
2
3
4
5
6
7
private RabbitTemplate rabbitTemplate;
public void testFanout() throws InterruptedException {
rabbitTemplate.convertAndSend("logs", "", "这是日志广播");
}
消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class FanoutCustomer {
(bindings = (
value = , //创建临时队列
// 绑定交换机,并指定交换机类型
exchange = (name="logs", type = "fanout")
))
public void receive1(String message){
System.out.println("message1 = " + message);
}
(bindings = (
value = ,
exchange = (name="logs",type = "fanout")
))
public void receive2(String message){
System.out.println("message2 = " + message);
}
}
5.4 Route 路由模型
生产者
1
2
3
4
5
6
7
private RabbitTemplate rabbitTemplate;
public void testDirect(){
rabbitTemplate.convertAndSend("directs", "error", "error 的日志信息");
}消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class DirectCustomer {
(bindings ={
(
value = (),
// 指定路由key
key = {"info", "error"},
exchange = (type = "direct", name = "directs")
)})
public void receive1(String message){
System.out.println("message1 = " + message);
}
(bindings ={
(
value = (),
key = {"error"},
exchange = (type = "direct", name = "directs")
)})
public void receive2(String message){
System.out.println("message2 = " + message);
}
}
5.5 Topic 订阅模型(动态路由模型)
生产者
1
2
3
4
5
6
7
8
9
10
private RabbitTemplate rabbitTemplate;
//topic
public void testTopic(){
rabbitTemplate.convertAndSend("topics",
"user.save.findAll",
"user.save.findAll 的消息");
}
消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class TopCustomer {
(bindings = {
(
value = ,
key = {"user.*"},
exchange = (type = "topic", name = "topics")
)
})
public void receive1(String message){
System.out.println("message1 = " + message);
}
(bindings = {
(
value = ,
key = {"user.#"},
exchange = (type = "topic", name = "topics")
)
})
public void receive2(String message){
System.out.println("message2 = " + message);
}
}
6. 消息可靠性
如何保证生产者生产的消息能被消费者100%消费?
问题:
- 如果消息已经到达RabbitMQ,但RabbitMQ宕机了,消息是不是就丢了?不会,RabbitMQ的Queue有持久化机制。
- 消费者在消费消息时,如果执行到一半,消费者宕机了怎么办?手动ACK。
- 如果生产者发送消息时,由于网络原因,导致消息没发送到RabbitMQ,该怎么办?
6.1 Confirm机制
解决第3问的办法:RabbitMQ提供了事务操作和Confirm操作。
RabbitMQ的事务:事务可保证消息100%传递。可以通过事务的回滚去记录日志,后面定时再次发送当前消息。但是事务的操作,效率太低。(加事务效率要降低100倍以上,所以不建议用)
Confirm:确认机制。效率比事务高。
保证把消息到达Exchange。不能保证消息被Exchange分发到指定Queue1.普通Confirm方式:发送一个消息的时候,等待对方告诉自己是否发送成功。
2.批量Confirm方式:发送多个消息的时候使用。
3.异步Confirm方式:推荐使用。
6.1.1 普通Confirm方式
生产者:开启confirm、waitForConfirms判断
1 | // 常规操作 |
6.1.2 批量Confirm方式
生产者:开启confirm、waitForConfirmsOrDie反馈
1 | // 常规操作 |
6.1.3 异步Confirm方式
生产者:开启confirm、addConfirmListener
1 | // 常规操作 |
6.2 Return机制
Confirm机制只保证把消息发送到Exchange上。而消费者监听的是消息队列。且Exchange不能持久化消息,Queue是可以持久化消息。
若Exchange发消息发给队列的过程中出现了错误,该怎么办呢?
Return机制:采用Return机制来监听消息是否从Exchange送到了指定的Queue。
6.2.1 使用Return机制
添加Return监听器、配置Return回调方法,开启Return机制
1 | // 常规操作 |
6.3 confirm、Return机制在SpringBoot中的应用。
1.修改配置
1 | spring: |
2.配置类
1 | /** |
3. 生产者消费者还是和原来一样。不用改动
6.4 避免重复消费消息
重复消费消息:消费者没有给RabbitMQ一个ACK。
消费者C1从RabbitMQ拿到消息msg1,当他消费成功后,会向RabbitMQ返回ACK。但是由于某种原因,消费者C1未返回ACK。RabbitMQ会认为C1未成功消费msg1,就会把此msg1发给C2。导致msg1被执行了2次。
重复消费带来的问题:
- 业务是幂等性操作:重复消费消息,对此业务没有任何影响。(幂等性操作:如删除和修改,执行一次和执行n次是没有区别的)
- 业务是非幂等性操作:要保证消息不会被重复消费。(非幂等性操作:如添加数据,且主键还是自增的)
解决方法:引入Redis
消费者C1从RabbitMQ拿到消息msg1,先把msg1的id放到Redis里面(id作为key,值为状态码),然后再执行其业务。
- id - 0 (正在执行业务)
- id - 1 (业务执行成功)
当C1消费成功后,未向RabbitMQ返回ACK。RabbitMQ会把消息msg1交给C2。C2从RabbitMQ拿到消息msg1,把msg1的id放到Redis里面时,发现此id已经存在了。
然后根据id的value可以得到以下两种情况:
- 值为0:这个消息msg1正在被消费中。
- 值为1:这个消息msg1已经被消费完了。
C2根据id所对应的状态值,决定是否消费msg1(0:C2什么都不做,1:直接向RabbitMQ发ACK)。
上述解决方法还存在一个问题:C1收到msg1并且执行过程中,C1出现死锁,导致C1一直处于执行业务状态,不成功也不失败,id一直存在Redis里面。解决方法,给存到Redis的id加上生存时间,如10ms。
1.生产者:
1 | channel.queueDeclare("hello", true, false, false, null); |
2.消费者:
1 | channel.queueDeclare("hello", true, false, false, null); |
6.4.1 用SpringBoot实现
1.生产者
1 |
|
2.消费者
1 |
|
7. MQ的应用场景
7.1 异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种 1.串行的方式 2.并行的方式。
串行方式:将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端。 这有一个问题是:邮件、短信并不是必须的,它只是一个通知。而这种做法让客户端等待没有必要等待的东西。
并行方式:将注册信息写入数据库后,同时发送邮件和短信,以上三个任务完成后,返回给客户端。并行的方式能提高处理的时间。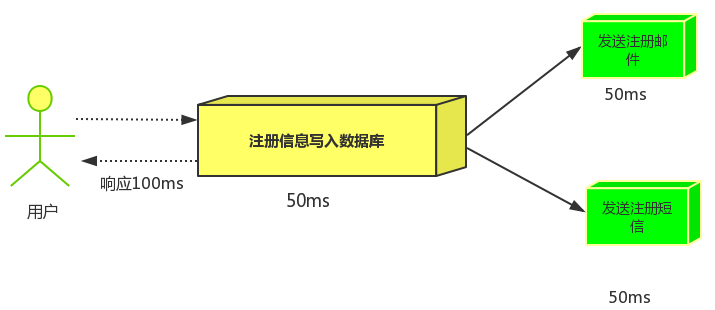
消息队列:假设三个业务节点分别使用50ms,串行方式使用时间150ms,并行使用时间100ms。虽然并行已经提高的处理时间。但是,前面说过,邮件和短信对我正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,应该是写入数据库后就返回。消息队列: 引入消息队列后,把发送邮件,短信不是必须的业务逻辑异步处理 。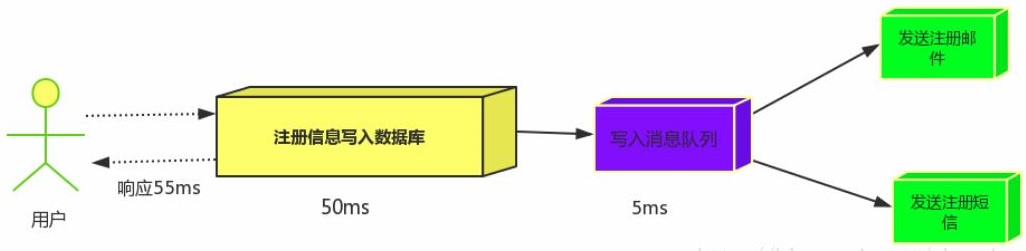
由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计)。引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
7.2 应用解耦
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口。

这种做法有一个缺点:当库存系统出现故障时,订单就会失败。 订单系统和库存系统高耦合。
引入消息队列:
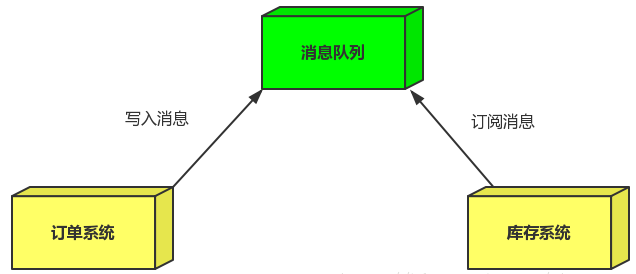
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失。
7.3 流量削峰
场景: 秒杀活动,一般会因为流量过大,导致应用挂掉。为了解决这个问题,一般在应用前端加入消息队列。
作用:
可以控制活动人数,超过此一定阀值的订单直接丢弃(我为什么秒杀一次都没有成功过呢^^)
可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)

1.用户的请求,服务器收到之后,首先写入消息队列。加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面。
2.秒杀业务根据消息队列中的请求信息,再做后续处理。
7.4举例
当系统A添加一个用户完成后,存到消息队列。然后系统B从消息队列里面拿。
7.4.1 配置文件(系统A、系统B共有)
1 | # RabbitMQ部分的配置 |
7.4.2 配置类(系统A、系统B共有)
1 |
|
7.4.3 Service层(系统A)
1 |
|
7.4.3 消费者模块(系统B)
1 |
|
8. RabbitMQ的集群
8.1 集群架构
8.1.1 普通集群(副本集群)
RabbitMQ代理操作所需的所有数据/状态都在所有节点之间复制。消息队列是一个例外,消息队列默认情况下位于一个节点上,尽管它们在所有节点上都是可见且可访问的。在集群(cluster)中的节点之间复制队列。
即主节点中所有数据都可以复制到从节点。但是主节点的消息队列无法复制到从节点,虽然从节点能看到主节点消息队列上的数据。(要实现高可用,看后面的镜像集群)
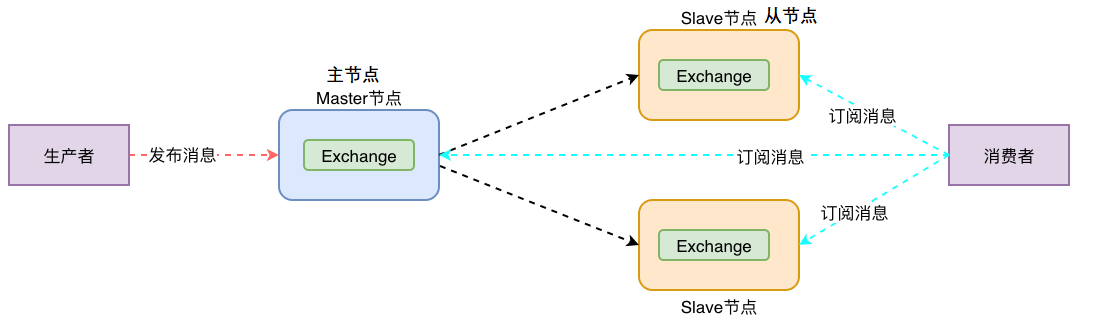
核心解决问题: 当集群中某一时刻master节点宕机,可以对Quene中信息,进行备份。
1 | # 0.集群规划 |
8.登录管理界面,展示如下状态:
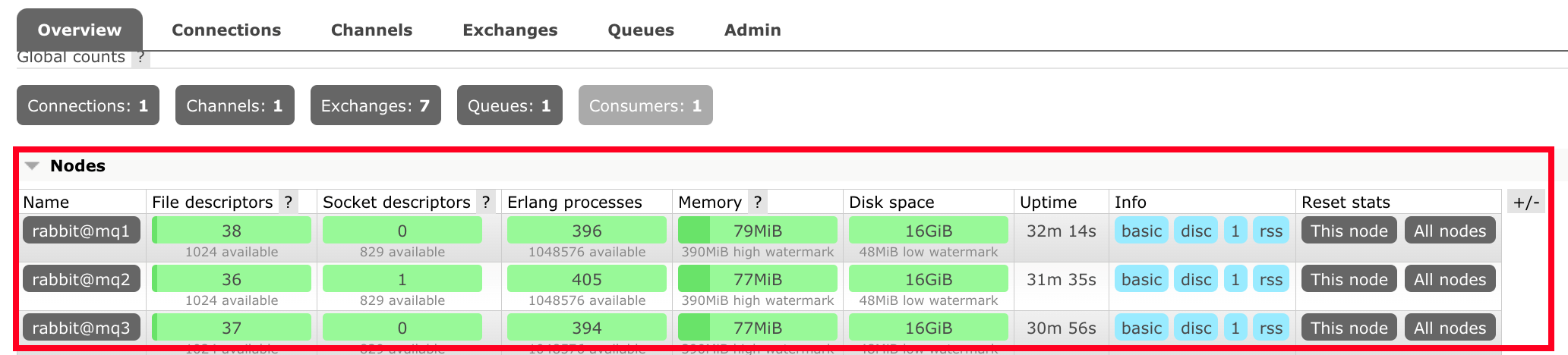
9.测试集群在node1上,创建队列
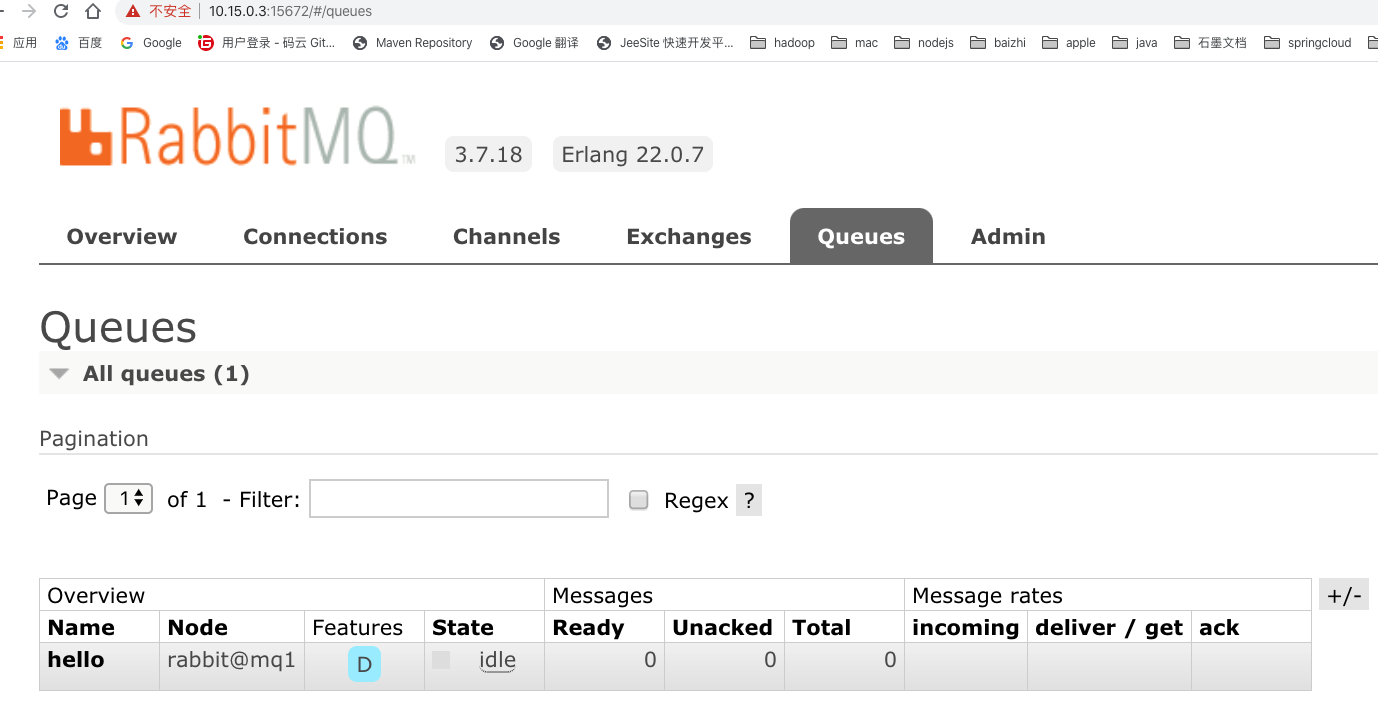
10.查看node2和node3节点:都有刚刚主节点创建的队列
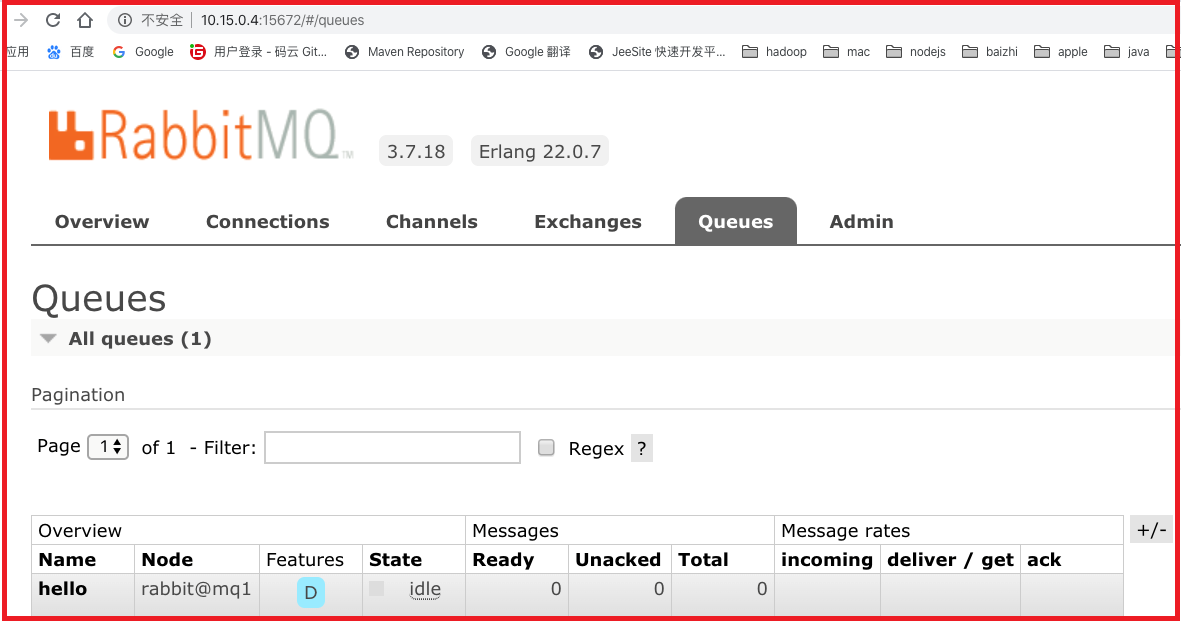
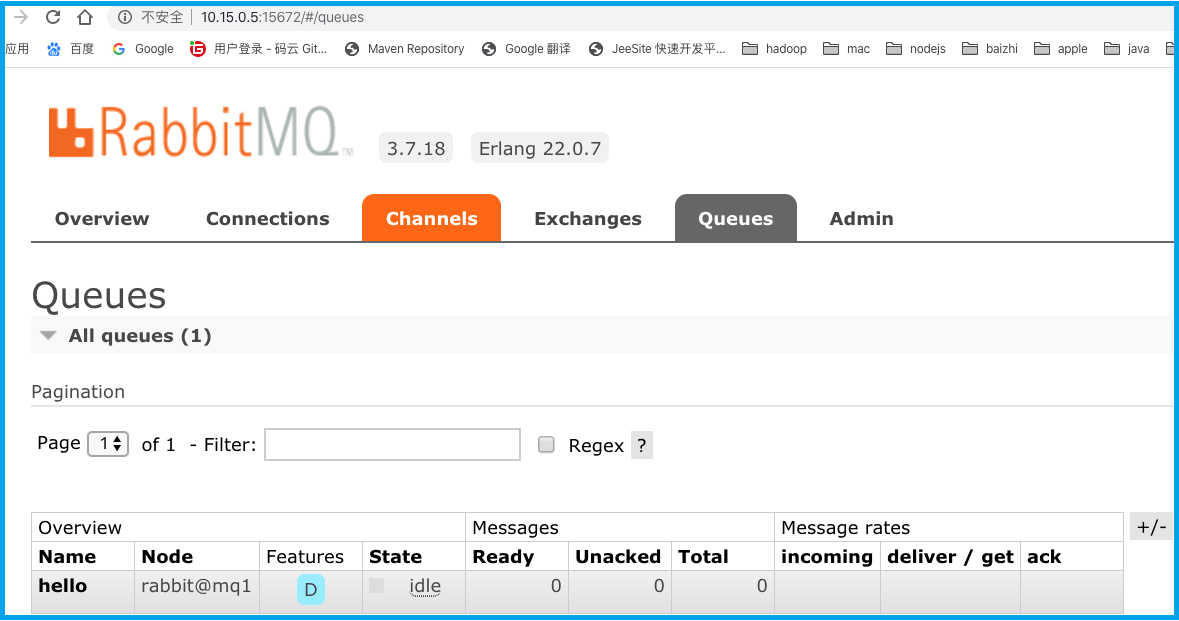
11.关闭node1节点,执行如下命令,查看node2和node3:
1 | rabbitmqctl stop_app |


{kind=link}