1.缓存的引入
Memcached(缓存) + MySQL + 垂直拆分(读写分离)
网站80%的情况都是在读,每次都去查数据库的话十分麻烦。缓存就是减轻数据的压力,解决读的问题。
发展过程:优化MySQL底层数据结构和索引 –> 文件缓存(IO)–> Memcached(当时的热门技术)
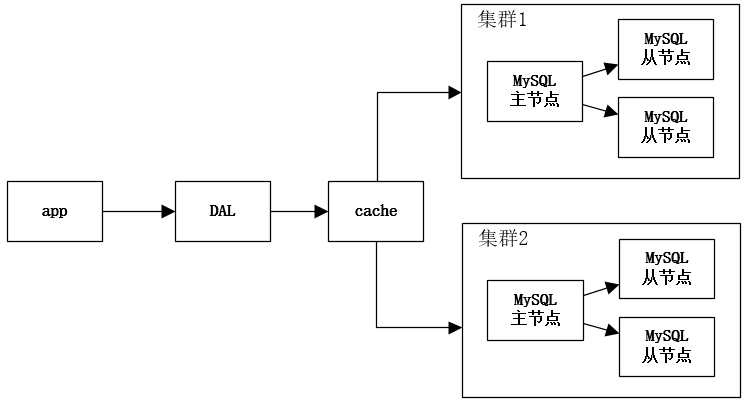
分库分表 + 水平拆分 + MySQL集群
每个集群里放1/2的用户数据。分库分表解决写的问题。
如今互联网
存储大文件:博客、图片等,会导致数据库表很大,读写效率低。如果有专门存储这些数据的数据库,MySQL的压力就会减少。
大数据:如一个表中有1亿条数据,表几乎无法更改。
一个基本的互联网项目
为什么要用NoSQL
用户的个人信息、社交网络、地理位置。用户自己产生的数据,用户日志等 爆发式增长!
这个时候就要用到NoSQL数据库来应对以上情况。
2.什么是NoSQL
NoSQL
NoSQL:Not Only SQL(不仅仅是SQL),泛指非关系型数据库。【关系型数据库:表(行,列)】
很多的数据类型如:用户的个人信息、社交网络、地理位置等。这些数据类型的存储不需要一个固定的格式,不需要多余的操作就可以横向扩展。如java可以使用Map<key, value>来控制。
NoSQL特点:
解耦!
方便扩展(数据之间没有联系,很好扩展)
大数据量性能高(Redis一秒写9万次,读11万次)
数据类型多样化(无需事先设计数据库,随取随用)
传统关系型数据库 与 NoSQL对比
关系型数据库: 结构化组织 数据和关系都存在单独的表中 数据库操作语言 严格的一致性 基础的事务 NoSQL: 不仅仅是数据库 没有固定的查询语言 键值对存储、列存储、文档存储、图形存储 最终一致性 高性能、高可用、高可扩
没有什么是加一层解决不了的:
# 1.商品分类信息
名称、价格、商家信息:关系型数据库就能解决。
# 2.商品的描述、评论(文字比较多)
文档型数据库:MongoDB
# 3.图片
分布式文件系统 FastDFS
- 淘宝自己的 TFS
- Google的 GFS
- Hadoop HDFS
- 阿里云 oss
# 4.商品的关键字(用于搜索)
- 搜索引擎 solr elasticsearch
# 5.商品热门的波段信息
- 内存数据库
- Redis、Tair、Memache...3.NoSQL四大分类
1.KV键值对
- Redis、Tair、memache
2.文档型数据库:bson格式(和json格式一样)
- MongoDB
- MongoDB是一种基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档。
- MongoDB是一种介于关系型数据库和非关系型数据库之间的产品
- ConthDB
3.列存储数据库
- HBase
- 分布式文件系统
4.图形关系数据库
- 放的不是图片,放的是关系:如社交拓扑图。
- Neo4j、infoGrid

